

来源:投资界
先从港股戏剧性的一幕说起。
今年先后上市的两家中国大模型公司,智谱和MiniMax,意外地走出了截然不同的曲线——
这一边,智谱持续大涨,一举跻身万亿俱乐部,上市短短几个月不经意间涨了20倍。那一边,MiniMax也曾有过市值突破4000亿港元的高光时刻,但如今股价从高点回撤超过60%。悄然间,“港股大模型双雄”之间最新的估值差距超过7倍。
与此同时,大洋彼岸两个巨无霸IPO迎面走来。
今年6月,Anthropic和OpenAI几乎同时向美国证监会提交了上市申请。两家公司最近一轮估值分别是9650亿和8520亿美元,预计今年秋季先后挂牌。这是frontier AI领域第一次有两家头部公司同时进入定价窗口,也是市场第一次拿到足够密度的财务数据来回答一个基础问题:
一家大模型公司到底值多少钱?
如果放在半年前,这个问题看起来没什么悬念。彼时市场共识很统一:Anthropic赢了。到4月,它的年化收入达到300亿美元,超过了OpenAI的250亿。Epoch AI此前预测,Anthropic的收入要到8月才能反超OpenAI,结果提前了四个月。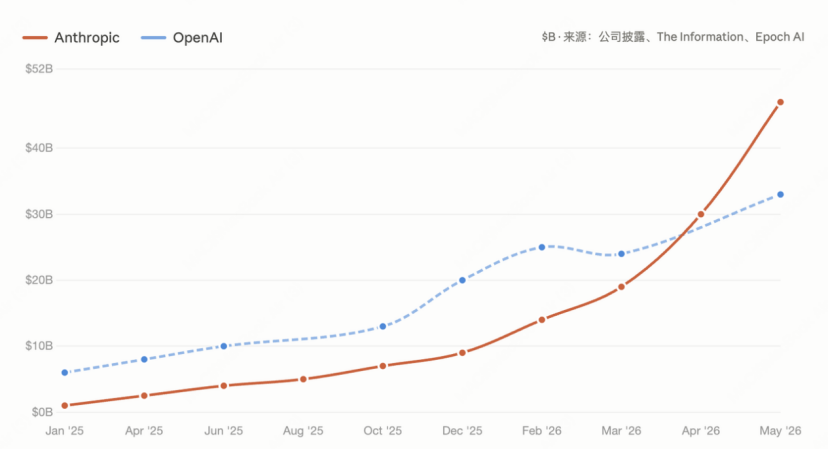 但5月开始,形势发生了变化。同一时期,OpenAI回过了劲。The Information报道其前五个月的月收入增长超过50%,编程工具Codex周活三个月涨了五倍。按ARR口径,Anthropic仍然领先OpenAI约35%,优势还在,但年初看上去板上钉钉的格局,到年中已经松动了。
但5月开始,形势发生了变化。同一时期,OpenAI回过了劲。The Information报道其前五个月的月收入增长超过50%,编程工具Codex周活三个月涨了五倍。按ARR口径,Anthropic仍然领先OpenAI约35%,优势还在,但年初看上去板上钉钉的格局,到年中已经松动了。
同时,微软在6月对媒体确认,正在评估把DeepSeek的开源模型接入Copilot来降低推理成本,当全球最大的AI产品分发入口开始认真考虑用一家中国创业公司的模型来压成本,行业关注的核心问题已经开始从“谁的模型最强”向“谁的成本最优”发生转化。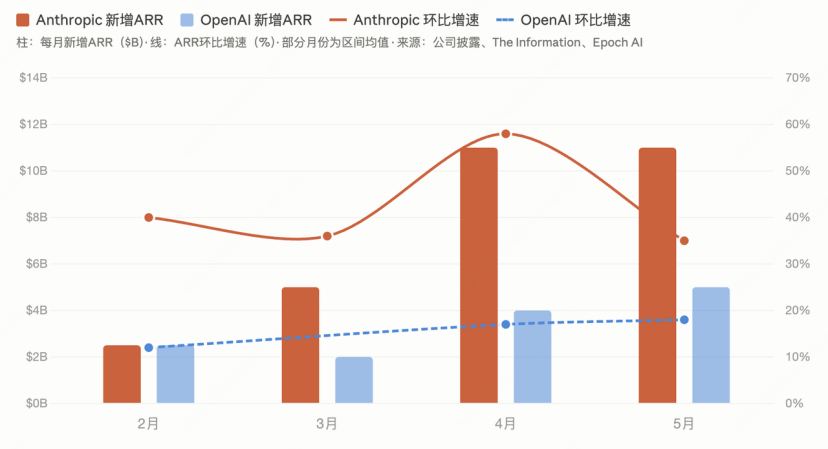 由此看下来,全球AI公司正进入定价窗口。只是我们将目光拉回最熟悉的两家公司,智谱与MiniMax这7倍的差距在定价什么?它反映的是两家公司的真实距离,还是一个尚未成熟的市场用一套不完整的工具给出的暂时性结果?这个困惑相信萦绕在大多数人心里。
由此看下来,全球AI公司正进入定价窗口。只是我们将目光拉回最熟悉的两家公司,智谱与MiniMax这7倍的差距在定价什么?它反映的是两家公司的真实距离,还是一个尚未成熟的市场用一套不完整的工具给出的暂时性结果?这个困惑相信萦绕在大多数人心里。
7倍差距在定价什么
在当前阶段,任何大模型公司的估值都和传统基本面关系不大,远没到能用P/S或P/E估值法来定价的阶段。智谱2025年收入7.24亿人民币,MiniMax约5.6亿人民币。两家亏损规模均远大于收入,流通盘很小,上市时间短,尚未进入解禁期。
在基本面无法支撑估值的阶段,市场需要一个简单、可传播、能快速形成共识的锚。是否能成为Coding SOTA 承担了这个角色。一家公司的模型在SWE-bench Pro或Code Arena上排到第几,几乎直接决定了它在二级市场被归入哪一档。传播链极短,说服力极强。
在这个锚上,智谱无疑在对的时间点打出了一张好牌。
6月中旬,Anthropic的Fable 5因出口管制被下架,几乎容易时间,GLM-5.2发布并开源,直接填上了全球开发者社区里突然出现的空缺。在SWE-bench Pro上,GLM-5.2得分62.1%,超过GPT-5.5的58.6%,在多个主流coding排行榜上拿到了第一或在场最高分。这个成绩在国内是独一档的,无论对比DeepSeek、MiniMax还是Kimi,GLM在coding领域目前都是最强的。
商业化数据也在同步验证。智谱在Q1的API定价上调83%,调用量仍然增长400%。MaaS平台ARR约17亿元人民币,12个月涨了60倍。排行榜上的领先、开源生态的卡位、加上定价权的验证,种种便是智谱万亿叙事的核心支撑。
而MiniMax在同一个锚上没有交出同样的牌。
M3在6月1日发布,SWE-bench Pro 59.0%超过了GPT-5.5,BrowseComp 83.5超过了Opus 4.7,从绝对能力看已经进入frontier tier。但M3上线同步调整了Token Plan计费规则,用户发现可用额度大幅缩水,事先没有预告,社区反应激烈。发布当天早盘高开7%,收盘跌了15%, 这一天的讨论几乎全部被计费争议占据了,M3作为模型本身的表现根本没有得到充分讨论,市场对它的第一印象就是负面的。
同样是涨价,智谱Q1把API定价上调了83%,过程平稳,没有引发类似的反弹,差别在于智谱是提前调价、逐步传导,而MiniMax是跟模型发布捆在一起、没有预告。市场给一次模型发布定价的窗口往往只有一两天,两家公司在定价管理上的成熟度差距,在这个窗口里被过分放大了。
7倍差距的核心逻辑是清晰的:智谱的GLM 5.2发布超预期,交出了国内最强的成绩,商业化数据也在同步验证;MiniMax的模型能力合格但没有超出预期,定价事件又进一步压缩了市场给它的估值空间。在当前这个阶段,这个解释显然是成立的。
问题是,这个差距能维持多久?
领先的保质期,很短
全球范围的证据已经反复说明一件事:coding领域的领先保质期很短。
Anthropic年初是公认的coding之王,Claude Code在enterprise coding市场拿到了42%到54%的份额。到了5月,增速就开始放缓,而同期OpenAI的Codex周活三个月涨了五倍。从Opus 4.5发布到GLM-5.2在coding上追平它,间隔只有204天。国内的轮转更快——过去12个月,coding排行榜的榜首换过多次,每一次重大模型发布都会重新洗一遍牌。
技术上也解释得通。Coding能力高度依赖训练数据配比和后训练策略,和基础架构上的原创性突破不同,这是一个资源密集但周期短的工程问题。一项能力的任务定义、评测方法、数据路径和商业价值一旦被验证,所有基础模型公司都会迅速投入。一次领先不会自然形成永久壁垒。
根源在于代码的输出可以被编译器和测试用例自动判定对错。这意味着训练信号的供给几乎没有瓶颈,能构造多少编程题,训练循环就能跑多长。这是过去两年内coding进步最快的原因。而同一个属性也决定了它的壁垒结构:自动验证意味着任何有算力的团队都能独立构造大规模训练信号,不依赖独占的标注数据或私有评测体系。训练信号可复制,建立在这些信号之上的训练方法就可以被系统性复制。
M2.7到M3的变化是一个直接的观察窗口。MiniMax此前不以coding见长,M2.7在主流评测中不突出。M3开始一个版本就从非重点领域进入了frontier tier,SWE-bench Pro直接超过了GPT-5.5,BrowseComp超过了Opus 4.7。
值得注意的是,M3在追赶coding的同时,效率指标也没有被牺牲。M3是428B总参数的MoE架构,GLM-5.2是744B,DeepSeek V4-Pro是1.6T。三家在SWE-bench Pro上分别做到59.0%、62.1%、55.4%,参数量最小的模型拿到了中间的分数。据NVIDIA技术博客的测试数据,M3的MSA架构在1M上下文下把每token计算量压到了上代的二十分之一。对一家还在追赶的公司来说,用更少的参数打出接近的成绩,意味着同样的算力预算能支撑更快的迭代节奏。
当然,差距仍然存在。Artificial Analysis的综合Intelligence Index上,GLM-5.2得分51,M3得分44。GLM在coding上的领先是真实的,M3在coding单项上接近但综合能力尚有距离。M3已经部分验证了追赶速度,但追赶还没有完成。
市场目前给这个追赶能力的定价权重接近零,7倍差距隐含的假设是当前的领先会持续甚至扩大。这个假设是否成立,取决于下一个版本的实际表现。但从全球行业的规律来看,coding领域单项能力的领先窗口通常以月计算。
另一个还没有被定价的维度
之前都在聊Coding,但大模型公司的价值不只有coding一个维度。在LLM国内商业化仍然深陷价格战的时候,视频生成可能已经悄悄跑出了一条不同的路。
晚点6月的一篇报道披露了一组数据:字节Seedance的毛利率达到70%,每卖出10元API调用,服务器和推理成本约占3元。核心算法团队仅十余人,视频模型的训练投入大约是语言模型的三分之一到五分之一。广告素材、短剧制作、电商内容、自动驾驶训练数据,每一个场景都指向确定的B端采购预算。头部漫剧公司使用Seedance的算力成本在5万元左右。
作为对比,国内LLM经历了两年价格战,豆包每天超过2亿人在用,日收入不足百万元,运行成本超过整个B站的经营支出。70%的毛利率,在LLM赛道几乎不可想象。
当然,这个数字需要限定。毛利率主要取决于折旧怎么算,字节的主要成本来自自建数据中心和自购芯片,芯片按几年折旧会显著影响账面成本。Seedance和快手可灵的收入增速在5月也都出现了放缓,可灵的ARR在冲到5亿美元后进入了平台期。但毋庸置疑的是,视频生成的变现路径比LL M更短。
MiniMax的Hailuo系列截至2025年底累计生成超过6亿个视频。跟Seedance一样,多模态业务的利润结构明显优于文本,据高盛估算,MiniMax的多模态API毛利率60%到70%,文本API约40%,2025年MiniMax的整体毛利率从12.2%升至25.4%。下一代视频模型H3预计近期发布。Hailuo最终能否复制Seedance的利润结构,还需要更多季度的数据来观察。
但视频生成这个维度在二级市场还几乎没有被独立定价。公开消息显示,快手正在以150亿美元的投前估值分拆可灵AI做Pre-IPO融资,计划即将港股上市,港股还在做交易视频生成平台的准备。
说到底,定价共识还没有形成
眼前,全球资本市场正在共同面对一个问题:怎么给大模型公司定价。
大模型公司是一类全新的资产,收入极小,亏损极大,技术迭代以月为周期,竞争格局每个季度都在变,传统的估值框架几乎完全失效。但与此同时,这个行业的增长速度也是前所未有的:Anthropic用15个月把年化收入从10亿做到了470亿,全球enterprise AI支出正在以每年翻倍的速度扩张,视频生成在半年内就跑出了70%毛利率的商业模型。一个跑得这么快的行业,定价方法本身也在快速迭代的过程中。
即便是在美股,定价共识也远没有形成。
OpenAI最近一轮私募估值8520亿美元,对应约35倍的预测收入倍数。桥水基金首席投资官格雷格·詹森(Greg Jensen)公开表示,这个倍数是在为“尚不存在的垄断结果”买单。但市场上同样有人认为,如果OpenAI能在2030年前实现千亿美元级收入,今天的价格回头看反而便宜了。同一家公司,同一批数据,看多和看空的理由都很充分。连华尔街最成熟的投资人之间都存在这样的分歧,说明给大模型公司定价这件事,全球都还在摸索。
但港股的处境更极端一些。可供交易的纯正大模型标的只有两家,流通盘极小,解禁期尚未到来。在这种市场结构下,一次模型发布、一次计费调整、一个排行榜更新,任何单一事件对价格的影响都会被成倍放大。
7倍的估值差距里,有多少反映的是两家公司的真实距离,有多少是市场结构本身造成的噪音,现在很难分得清。橡树资本创始人、巴菲特公开推荐的投资人霍华德·马克斯说过:决定投资结果的不是买到的东西好不好,而是买入时价格里装了多少预期。价格总是在反映已经发生的事,但决定它接下来走向的,是那些还没有发生的事。
唯一可以确定的是,当解禁期到来、流通盘扩大、更多AI公司在港股和A股上市之后,当前的价格秩序,会面临重新校准。